|
|
[Seminarthemen WS08/09] [ < ] [ > ] [Übersicht]
Nachdem in den vorhergehenden Kapiteln bereits die modellgetriebene Softwareentwicklung im Allgemeinen sowie die Nutzung des Frameworks openArchitectureWare im Besonderen vorgestellt wurde, soll nun eine Beispielanwendung mit Hilfe von openArchitectureWare umgesetzt werden. Nach der Identi&64257;zierung der zu erzeugenden Artefakte in den ersten beiden Abschnitten die wird anschließend die Modellierung sowie die Entwicklung von geeigneten Generatoren beschrieben. Abschließend werden mögliche Weiterentwicklungen des Beispiels vorgestellt.
Eine Stammdatenp&64258;ege zeichnet sich in der Regel dadurch aus, dass ihre Struktur weitgehend von den zu bearbeitenden Daten und damit von dem zugrundeliegenden Datenmodell bestimmt werden. Spezielles Verhalten sowie besondere fachliche Logik werden hingegen nur selten benötigt. Dadurch eignet sich ein modellgetriebenes Vorgehen insbesondere aus den folgenden Gründen:
Der Einsatz von Modellen dient folglich der Abstraktion von der fachlichen Domäne des zugrundeliegenden Datenmodells. Hinsichtlich der aus den Modellen zu erzeugenden Funktionalität werden die folgenden Anforderungen an die Anwendung gestellt:
Die Implementierung des Beispiels basiert auf einer Stammdatenp&64258;ege von Peemöller [Pee07], die im folgenden Abschnitt beschrieben wird. Diese Anwendung wurde insbesondere deshalb ausgewählt, weil sie das oben genannte Standardverhalten vorgibt. Dies führt dazu, dass der Fokus zunächst auf das Datenmodell gelegt werden kann und die Anwendung ohne manuelle Implementierung lau&64256;ähig ist. Die Realisierung von abweichendem Verhalten wird in diesem Beispiel nicht adressiert, jedoch in den möglichen Weiterentwicklungen aufgegri&64256;en.
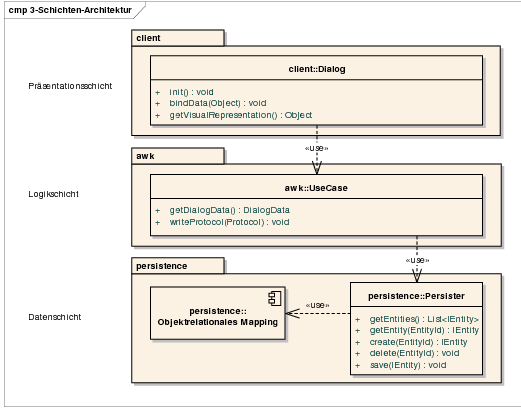
Architektur Die Anwendung ist als klassische 3-Schichten-Architektur realisiert (vgl. Abbildung 13):
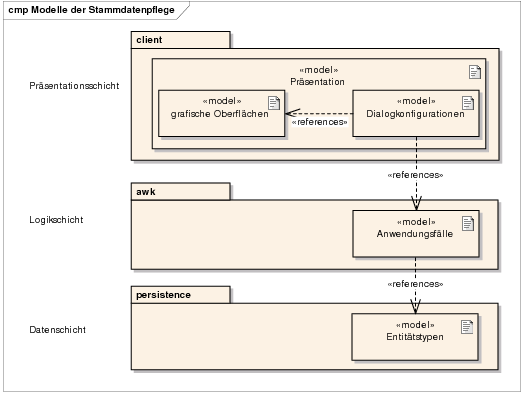
Modellsteuerung Um die Fachlichkeit der resultierenden Anwendung zu beschreiben, werden vier unterschiedliche Modelltypen verwendet (vgl. Abbildung 14). Sämtliche Modelle sind als XML-Dokumente realisiert und werden zur Laufzeit eingelesen und verarbeitet.
Somit sind für eine vollständige fachliche Parametrierung der Anwendung die folgenden vier XML-Modelle zu generieren:
Die in den Anforderungen genannte Möglichkeit, eigene Aufzählungstypen zu de&64257;nieren, ist in der Anwendung nicht über Modelle möglich. Hierzu ist zusätzlich eine Java-Klasse zu generieren, die eine entsprechende Zuordnung auf Hibernate-spezi&64257;sche Persistenzaspekte realisiert.
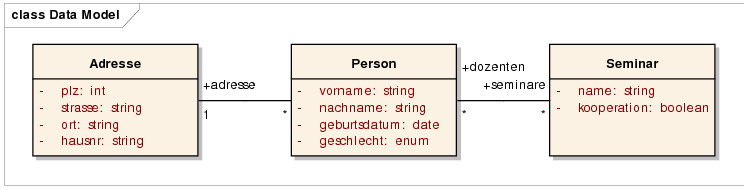
Nachdem in dem vorangegangenen Abschnitt die Artefakte analysiert wurden, die später zu generieren sein werden, folgt nun die Entwicklung des Metamodells. Das Metamodell soll es erlauben, die folgenden Bestandteile zu modellieren:
Für die spätere Modellierung soll eine textuelle DSL verwendet werden, da damit eine schnelle Modellerstellung gewährleistet ist, bei der zusätzlich die Möglichkeit des Kopierens ähnlicher Modellteile möglich ist.
In Listing 26 ist ein Xtext-Modell der Sprache SDDSL angegeben, die die oben genannten Anforderungen erfüllt. Die Sprachelemente leiten sich direkt aus den Anforderungen ab und sind somit weitgehend selbsterklärend. Für die Vorgabe von Datentypen für einfache Attribute wurde in den Zeilen 23–28 ein Aufzählungstyp de&64257;niert. Da einfache und selbstde&64257;nierte Datentypen von Attributen teilweise unterschiedlich behandelt werden müssen, werden diese durch unterschiedliche Klassen repräsentiert.
| Listing 26: | Xtext-Modell für das Datenmetamodell |
Somit sind die abstrakte und konkrete Syntax des Metamodells spezi&64257;ziert. Durch die Verwendung von Kreuzreferenzen (eckige Klammern in den Zeilen 36 und 39) wird zudem sichergestellt, dass die referenzierten Aufzählungs-, Entitäts- oder Beziehungstypen existieren. Diese Bedingungen bilden bereits einen Teil der zu spezi&64257;zierenden Kontextbedingungen. Des Weiteren sind noch folgende Bedingungen zu erfüllen, um ein in der Anwendung valides Modell zu erhalten:
Zur Überprüfung dieser Kontextbedingungen wird die Sprache Check verwendet. Listing 27 de&64257;niert die oben angegebenen Kontextbedingungen als Check-Constraints.
| Listing 27: | Check-Constraints für das Datenmetamodell |
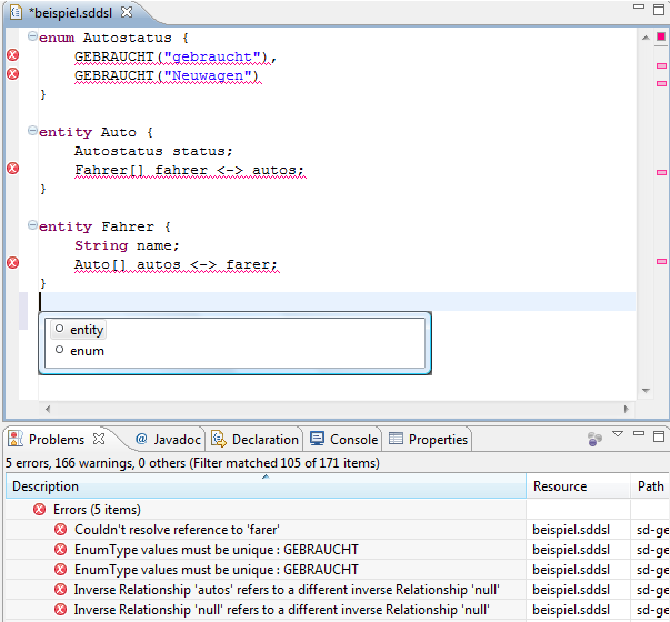
Nachdem nun das Metamodell als Xtext-Modell mit Check-Constraints spezi&64257;ziert ist, kann durch das openArchitectureWare-Framework ein entsprechender Editor generiert werden, der die Sprache SDDSL unterstützt. Abbildung 15 zeigt den erzeugten Editor bei der Bearbeitung eines Beispielmodells. Hervorzuheben ist die zur Verfügung gestellte Funktionalität wie Syntax-Highlighting (Schlüsselwörter wie enum), Code Completion (Vorschlagssystem; hier entity, enum) und die Überprüfung von Kontextbedingungen (Problems-View). Während der erste Fehler durch die Verwendung von Kreuzreferenzen gefunden wird, entsprechen die restlichen vier Fehler Bedingungen, die soeben mit Hilfe von Check formuliert wurden.
|
|
Für die Entwicklung des Generators kommen die Template-Sprache Xpand für die Codeerzeugung (Javaklassen sowie XML-Dokumente) sowie Xtend für eine Modellmodi&64257;kation zum Einsatz. Aus dem Modell sind die folgenden Artefakte zu generieren:
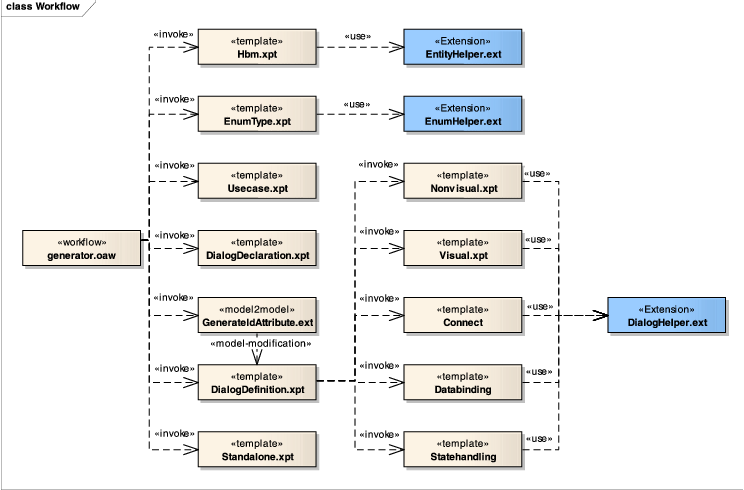
Einen Überblick über die verwendeten Templates bietet Abbildung 16. Die einzelnen Templates traversieren das vom Work&64258;ow instanziierte Modell und erzeugen entsprechend der Expansionsregeln spezi&64257;schen Code.
Der Aufruf der Templates erfolgt dabei von oben nach unten. Nach dem Aufruf des Templates „DialogDeclaration.xpt“ wird zudem eine Modellmodi&64257;kation durchgeführt. An dieser Stelle wird in dem Modell zu jedem Entitätstyp ein technisches Attribut „id“ hinzugefügt (vgl. Listing 28), um dieses in der Ober&64258;äche anzeigen zu können. Dieses Attribut ist in den Hibernate-Mappings bereits automatisch als Schlüsselattribut vorgesehen.
| Listing 28: | Modell-Modi&64257;kation: Hinzufügen eines ID-Attributs |
Anschließend wird die Ober&64258;äche über das Template „DialogDe&64257;nition.xpt“ erzeugt, das auf fünf Subtemplates aufgeteilt ist. Die Erzeugung von String-Identi&64257;katoren, die von den Subtemplates gemeinsam genutzt werden, ist in die Extension „DialogHelper.ext“ ausgegliedert.
Aus der Generatoraufteilung wird ersichtlich, wie einzelne Domänen durch das modellgetriebene Vorgehen getrennt werden können:
Als Beispiel für eine technische Domäne ist in Listing 29 ein Teil des Templates für die Erzeugung der Hibernate-Mappings angegeben. Die bei der Metamodellierung eingeführte Unterscheidung von Attributen in NormalAttribute und EnumAttribute erlaubt durch parametrische Polymorphie eine saubere Trennung der jeweiligen Subtemplates.
| Listing 29: | Template zur Erzeugung der Hibernate-Mappings (Ausschnitt) |
Auf eine detaillierte Vorstellung der weiteren Templates soll an dieser Stelle verzichtet werden, da diese jeweils spezi&64257;sche technische Aspekte behandeln und dies für das grundsätzliche Verständnis nicht essentiell ist. Der interessierte Leser sei an dieser Stelle auf die entsprechende Literatur ([Pee07], [Red07], [sof07]) verwiesen.
Mit der De&64257;nition der domänenspezi&64257;schen Sprache SDDSL und der Erstellung geeigneter Generatoren kann nun eine Stammdatenp&64258;ege zur Seminarverwaltung generiert werden. Dazu müssen zunächst im generierten Editor die zu bearbeitenden Daten modelliert werden, wie in Listing 30 angegeben.
| Listing 30: | Datenmodell der Seminarverwaltung als SDDSL-Modell |
Anschließend ist ein Work&64258;ow zu erstellen, der lediglich den bereits beim Generator erstellten Work&64258;ow „generator.oaw“ aufruft und die gewünschten Ausgabeverzeichnisse angibt. In dem in Listing 31 angegebenen Fall werden die Generierungsergebnisse der Projektstruktur der Anwendung folgend auf einzelne Ordner aufgeteilt.
| Listing 31: | Work&64258;ow der Seminarverwaltung |
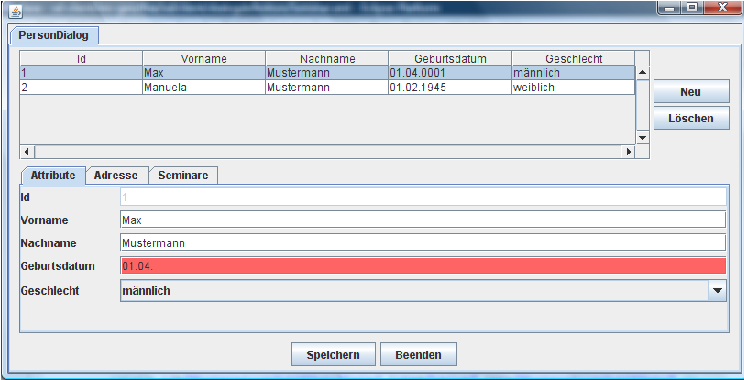
Nun können der Work&64258;ow ausgeführt und eine der generierten Standalone-Klassen gestartet werden. Abbildung 17 zeigt den soeben erzeugten Dialog für die P&64258;ege der Personendaten. Neben den hier abgebildeten Attributen ist es ebenso möglich, über die entsprechenden Reiter die Beziehungen zu bearbeiten. Bei den Attributen ist zusätzlich, wie in Abbildung 17 bei dem Geburtsdatum ersichtlich, eine einfache Eingabeüberprüfung generiert worden. Lassen sich die Eingaben nicht in den vorgesehenen Typ konvertieren, so wird die Eingabe farblich hervorgehoben.
Auch wenn diese Operationen bereits eine große Menge der anfallenden Aufgaben einer Stammdatenp&64258;ege abdecken mögen, so werden früher oder später spezi&64257;sche Funktionen zu realisieren sein. Eine Möglichkeit zur Integration von Verhalten besteht in der Deklaration von Callback-Methoden, die in der Ober&64258;äche an entsprechende Knöpfe gebunden werden. Des Weiteren ist ein entsprechender Controller zu generieren, in dem diese Methoden manuell zu implementieren sind. Dies kann beispielsweise über Protected Regions oder Vererbung geschehen. Eine davon unabhängige Strategie könnte es sein, die oben genannten Basisoperationen als Modellelemente einer neuen Sprache zu realisieren. Damit wäre es möglich, diese Operationen in einem Modell zu komponieren und die Logik erzeugen zu lassen. Beispiele hierfür wäre das Ausfüllen einer neuen Entität mit einer Menge an Vorgabewerten oder kaskadierendes Löschen in der Anwendung. Aufwand und Nutzen dieser Lösung sollten jedoch gewissenhaft gegeneinander abgewogen werden.
[Seminarthemen WS08/09] [ < ] [ > ] [Übersicht]