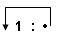
ones dienen, die eine unendliche Liste von Einsen als Resultat liefert.Ones
kann deshalb auch als Synonym für diese unendliche Liste verwendet werden.ones :: [Int] ones = 1 : ones
ones = 1 : ones ones = 1 : 1 : ones ones = 1 : 1 : 1 : ones usw. ...
ones bzw. der aus dieser Funktion
resultierenden unendlichen Liste als Graph ist insofern interessant, dass es sich um eine zyklische Struktur
mit folgendem Aussehen handelt:
more :: String
more = "More" ++ andmore
where andmore = "and more" ++ andmore
more handelt es sich wiederum um eine eine unendliche Liste. Bei der
Ausgabe des Funktionsergebnisses auf dem Bildschirm ergibt sich folgendes:
? putStr more
More and more and more and more and more and more and m{Interrupted}
more erfolgt intern wiederum als Graph in Form einer zyklischen Struktur.
ones kann auch mit Hilfe der Funktion repeat realisiert werde.repeat:
repeat x :: α -> [α] repeat x = x : reapeat x
ones mit Hilfe der Funktion repeat:
ones = repeat 1
ones ist korrekt, jedoch liefert die Auswertung in diesem Fall keine
zyklische Struktur. Die Ausgabe der ersten fünf Elemente würde nämlich folgendermaßen aussehen:
1 : 1 : 1 : 1 : 1 : repeat 1
repeat 1
durch 1 : repeat 1 ersetzt wird. Um eine zyklische Struktur zu erhalten, müßte die
Definiton von repeat in folgender Weise geändert werden:
repeat x = xs where xs = x : xs
iterate aufgegriffen werden, die bereits Gegenstand des
vorangegangen Kapitels war. Auch diese Funktion läß sich auf unterschiedliche Arten definieren. Die ursprüngliche Definition verwendet wie im zuvor behandelten
Beispiel ebenfalls keine zyklische Struktur. Durch eine abgewandelte Definiton läßt sie sich jedoch
auch in eine zyklische Struktur wandeln.
iterate f x = xs where xs = x : map f xs
iterate (2x) 1 ergibt sich folgendes Bild:
iterate (2x) 1

f x in O(1) Schritten ausgewertet werden kann, dann können die ersten
n Elemente von iterate f x in O(n) Schritten berechnet werden.iterate f x = x : map f (iterate f x)
iterate mit dieser Definition näher beleuchtet werden.
iterate (2x) 1 => 1 : map (2x) (iterate (2x) 1 ) => 1 : 2 : map (2x) (map (2x) (iterate (2x) 1 )) => 1 : 2 : 4 : map (2x) (map (2x) (map (2x) (iterate (2x) 1 )))
O(n²)
Schritte benötigt. In Fällen wie diesen ist es also sehr wichtig zyklische Strukturen zu verwenden,
um Effizienz zu wahren.
1, 2, 3, 4, 5, 6, 8, 9, 10, 12, 15, 16, ...
merge. Diese
Funktion erhält zwei unendliche Zahlenlisten in aufsteigender Ordnung als Argumente und überführt
diese in eine unendliche Zahlenliste in aufsteigender Ordung ohne Duplikate.
merge :: [Integer] -> [Integer] -> [Integer]
merge (x : xs) (y : ys) | x < y = x : merge xs (y : ys)
| x == y = x : merge xs ys
| x > y = y : merge (x : xs) ys
merge ist es sehr einfach die Funktion hamming
zur Lösung des Hamming Problems zu definieren.
hamming :: [Integer]
hamming = 1 : merge (map (2×) hamming)
(merge (map (3×) hamming)
(map (5×) hamming))
hamming wird durch folgende zyklische Struktur dargestellt:


n Elemente der Hamming Liste können in O(n) Schritten
ermittelt werden. Im Folgenden soll eine Verallgemeinerung des Hamming Problems dargestellt werden. Das heißt, die Zahlen
2, 3, und 5 sollen durch die willkürlichen, aber positiven Zahlen a, b, c ersetzt werden. Eine Funktion
die diese Anforderung erfüllt, ist die folgende:
hamming2 :: Integer -> Integer -> Integer -> [Integer]
hamming2 a b c = 1 : merge (map (a×) hamming2 a b c)
(merge (map (b×) hamming2 a b c)
(map (c×) hamming2 a b c))
O(n) Auswertungsschritten für n Elemente führt. Eine
effizientere, weil zyklische Struktur ist die folgende:
hamming2 a b c = hamming3
where hamming3 = 1 : merge (map (a×) hamming3)
merge (map (b×) hamming3)
(map (c×) hamming3))