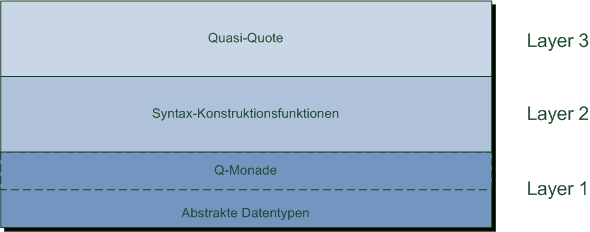
Die letzte bzw. oberste Schicht in der Architektur der Template Haskell Bibliothek bilden die Quasi-Quotes,
welche die eigentlichen Templates in Template Haskell bilden, denn:
Mithilfe der Quasi-Quotes ist es möglich, eine eigene domain-spezifische Syntax zum Erzeugen von Programm-Fragmenten
zu verwenden. Der Quasi-Quoter hat also die Aufgabe, eine abstrakte Syntax in Form eines Strings in einen Syntaxbaum
zu parsen. 18 Damit handelt es sich bei dieser Schicht um eine reine Komfort-Schnittstelle
für den Nutzer. Die Realisierung dieses Komforts bringt allerdings einige Probleme mit sich, auf die im Folgenden
eingegangen wird. Dabei wird zunächst der allgemeine Nutzen von Quasi-Quotes erläutert.
Quasi-Quotes allgemein
Das Prinzip der Quasi-Quotes wird anhand eines kleinen Beispiels deutlich.
Angenommen, man will eine abstrake Sprache zum Durchführen der vier Grundrechenarten implementieren. Der erste Schritt besteht darin,
eine Datentyp-Repräsentation für mathematische Ausdrücke zu entwickeln. Diese könnte bspw. wie folgt aussehen:
In einem zweiten Schritt muss nun ein Parser implementiert werden, der in der Lage ist, Ausdrücke wie z.B. 1 + 2
in den Datentyp Expr zu transformieren. An dieser Stelle wird nicht weiter auf die genaue Implementierung
eines solchen Parsers eingegangen, da es für das weitere Verständnis dieser Ausarbeitung nicht notwendig ist.
Es reicht, an dieser Stelle zu wissen, dass ein eigener Parser in der Lage sein muss,
Patterns und Ausdrücke aus der eigenen abstrakten Syntax zu unterscheiden.
Angenommen, die Funktion quoter erzeugt also einen solchen Parser für die mathematischen Ausdrücke, dann
kann dieser zur Auswertung des Strings 1 + 3 + 5 wie folgt aufgerufen werden19:
> [expr|1 + 3 + 5|]
BinopExpr AddOp (BinopExpr AddOp (IntExpr 1) (IntExpr 3)) (IntExpr 5)
Wie aus der Eingabe ersichtlich wird, hat ein Quasi-Quote die Form: [p|exp|], wobei p ein Parser und exp der zu parsende String ist.
Diese Notation wird auch Bracket-Schreibweise genannt.
Damit der Compiler Quasi-Quotes interpretieren kann, muss beim Kompilieren zusätzlich das Flag -XQuasiQuotes angegeben werden.
In der zweiten Zeile, der Ausgabe, ist der erzeugte Syntaxbaum angegeben.
Quasi-Quotes in Template Haskell
Zur Erzeugung von Haskell Templates stellt die Template Haskell Bibliothek eine Reihe von Quasi Quotern bereit,
welche in diesem Zusammenhang als Kontexte bezeichnet werden. Diese sind im Paket Language.Haskell.TH.Quote.QuasiQuoter definiert.
Für jeden Kontext wird ein eigener Parser verwendet, der durch einen der Buchstaben 'e','p','d' im Quasi-Quote für den
Platzhalter p eingesetzt wird. Bei fehlender Angabe eines Parsers wird implizit der Parser für Ausdrücke 'e' angenommen.
In Abhängigkeit des Parsers ändert sich die zulässige Syntax des Strings.
An dieser Stelle sei angemerkt, dass die Parser für Patterns und Typdefinitionen in der aktuell vorliegenden Template Haskell Version (2.5.0.0) noch nicht
funktionieren.
Überträgt man die monadische Version der Funktion cross in Quasi-Quotes, so
ergibt sich der folgende Code:
cross :: ExpQ -> ExpQ -> ExpQ
cross f g = [| \ (x,y) -> ($f x, $g y) |]
Die Bracket-Schreibweise erlaubt es dem Nutzer also gewöhnlichen Haskell-Code zu verfassen, der dann durch
den Compiler in einen ExpQ (also einen monadischen Ausdruck) übersetzt wird. Somit kann der Splice-Operator
$ auch auf Quasi-Quotes angewendet werden. Da cross
aber vom Typ ExpQ -> ExpQ -> ExpQ ist, Splices aber nur auf Ausdrücke vom Typ ExpQ
angewendet werden können, müssen die beiden Parameter f und g
zuvor gebunden werden. Hierbei fällt auf dass diese innerhalb des Templates wiederum in Form eines Splices
auftauchen.
Ein Splice innerhalb eines Quasi-Quotes bedeutet: Wenn beim Kompilieren eines Quasi-Quotes
ein Splice gefunden wird, dann wird dieser zu Compilezeit ausgeführt und der resultierende Ausdruck an dessen Stelle
eingefügt, so, als hätte der Entwickler diesen selbst eingegeben.20
Die Ausführung von Programmcode zur Compilezeit führt damit zu einem mehrstufigen Kompiliervorgang, auf den im
nächsten Kapitel näher eingegangen wird.
Aus dem folgenden Beispiel wird ersichtlich, dass man der Funktion cross als Parameter ebenfalls
Quasi-Quote Ausdrücke übergeben kann. In diesem Fall werden die Funktionen x und y
in Quasi-Quotes als Parameter verwendet.
> let x = (+)1
> let y = (*)1
> let foo = cross [|x|] [|y|]
:t foo :: ExpQ
> let bar = $foo
> :t bar
bar :: (Integer, Integer) -> (Integer, Integer)
> bar (1,2)
(2,2)
Da es sich bei foo um einen ExpQ handelt, kann man sich mithilfe der Funktion runQ
den erzeugten Syntaxbaum zu foo anzeigen lassen.
> runQ foo
LamE [TupP [VarP x_2,VarP y_3]] ( TupE [ AppE (VarE x_1627429000)
(VarE x_2),
AppE (VarE y_1627429038)
(VarE y_3)
]
)
Wie man erkennen kann, wurden die Template Variablen x und y auch hier korrekt umbenannt,
so dass es zu keinem Namenskonflikt mit den übergebenen gleichnamigen Funktionen aus einem anderen Scope kommt.
Grenzen von Quasi-Quotes
Das obige Beispiel zeigt, dass Quasi-Quotes eine gute Möglichkeit sind, um komplexe Ausdrücke automatisch vom
Compiler generieren zu lassen. Allerdings lassen sich mit den Quasi-Quotes nicht alle Sachverhalte darstellen,
sodass man oft weiterhin auf die Syntax-Konstruktionsfunktionen angewiesen ist. So ist bspw. jede Form der
Algorithmenkonstruktion nur mit Quasi-Quotes nicht umsetzbar. Man denke z.B. an die Konstruktion einer Funktion,
die bei einem beliebig langen Tupel das n-te Element ausgeben kann. Unter Kenntnis der Größe n des Tupels muss somit ein entpsrechendes
Pattern eingegeben werden. In Quasi-Quotes müsste man somit einen Ausdruck der Art [|\n (a1,a2,...,an) -> an |]
konstruieren; genau diese Konstruktion an der Stelle ... ist aber nicht möglich. Die Lösung dieses Problems
wird in dem Kapitel zu den Anwendungsbeispielen erörtert.
Da es sich bei der Syntax innerhalb der Quasi-Quotes um einfachen Haskell Code handelt, könnte man zu der Annahme kommen,
dass für diesen ohne großen Aufwand ein statisches (lexikalisches) Scoping durchgeführt werden kann. Ein Problem bei der
Umsetzung des Scopings, ist allerdings die durch die mehrstufige Kompilierung bedingte Erzeugung neuen Codes
zur Compilezeit. Es muss also die Frage beantwortet werden, wie Namenskonflikte, die durch die Expansion von
Templates in anderen Templates entstehen können, zu verhindern sind - die Antwort lautet: Pre-Expansions-Binding.
Konkret bedeutet dies, dass alle Namen eines Templates
lexikalisch an ihre Umgebung gebunden werden und zwar bevor das
Template expandiert wird.23
Durch Pre-Expansions-Binding werden sogenannte "unhygienische Macros" vermieden, bei denen die Expansion innerhalb
eines Programmes dazu führen kann, dass Bindings auf Objektebene überschrieben werden.24
Deutlich wird dies an dem folgenden Beispiel:
foo = \x -> $(f [| x |])
f :: ExpQ -> ExpQ
f e = [| \x -> $e |]
Die Expansion des Templates f im Ausdruck von foo würde - bei einem unhygienischen Macro - dazu führen, dass
x nicht mehr an das Pattern x der Lambda-Funktion von foo gebunden wird. Stattdessen expandiert
f selbst zu einer Lambda-Funktion, die das Binding für x überschreibt. Man erhielte somit für
foo den Ausdruck \x1 -> \x -> x.
Da Haskell - wie bereits erwähnt - jedoch alle Variablen vor der Expansion der Templates bindet, wird das im Template
f [| x |] verwendete x an die äußere Lambda-Funktion gebunden, womit foo gleichwertig ist zu dem Ausdruck
\x -> \x1 -> x
Die Tatsache, dass die Quasi-Quotes auf der Q-Monade basieren, führt dazu, dass Template-Variablen umbenannt werden,
damit diese nicht unbeabsichtigter Weise falsch gebunden werden können. Der Quasi-Quote [| \x -> \x -> x |] führt bei einem Splice
daher stets zu dem Ausdruck \x1 -> \x -> x. Wie kann man diese Ausdruck aber nun unter Verwendung des Templates f generieren?
Die Antwort auf diese Frage ist die Antwort auf eine andere Frage, nämlich: Wie kann das Pre-Expansions-Binding umgangen bzw.
umgewandelt werden in ein Post-Expansions-Binding, ein Binding also, dass erst nach der Expansion des Templates vorgenommen wird. Die Antwort lautet:
Dynamisches Binding. Da das dynamische Binding im Grunde nichts anderes ist als das bewusste Umgehen der sog. Cross-Stage-Persistenz, wird diese im folgenden
Abschnitt zunächst erläutert.