Request (Output / Ausgabe)
und Response (Input / Eingabe) wie folgt realisiert:type FilePath = String data Request = ReadFile FilePath | WriteFile FilePath
String |
... data Response = RequestFailed |
ReadSucceeded String |
WriteSucceeded |
... Request
und dem entsprechendem Response (keine Synchronisation)
Request durch übereifrige
Auswertung von Response Stream möglich IO a eine Aktion ist die - vor der Rückgabe
des Wertes vom Typ a - Input/Output durchführen
kann.type IO a = World -> (a, World) World
von der Aktion IO a bearbeitet und gibt eine veränderte
World mit dem Ergebnis a zurück.do Notation" gegeben, die praktischer ist,
weil man nicht den Operator (>>=) und die Lambda
Funtion verwenden muss.getTwoChars :: IO (Char, Char)getTwoChars = do { c1 <- getChar ;
c2 <- getChat ;
return (c1, c2) } (>>=) übersetzt
wird.(>>)
Kombintator implementieren:forever :: IO () -> IO ()forever a = a >> forever a(forever a) durch
rekursives Aufrufen von forever (sich selbst).forever, genauso wie die Kombinatoren
(>>) und (>>=), eine Aktion
als ein Argument, wodurch Kontrollstrukturen realisiert werden können.for :: [a] -> (a -> IO ()) ->
IO ()for [] fa = return ()for (n:ns) fa = fa n >> for ns
fa(for ns fa) wendet hier die Funktion fa
auf jedes Element von ns an und liefert jedesmal eine
Aktion, die in eine Liste eingefügt wird.for auch auf eine andere Weise definieren:for ns fa = sequence_ (map fa ns)sequence_ :: [IO a] -> IO ()sequence_ as = foldr (>>) (return ()) as map auf
jedes Element von ns die Funktion fa an und
gibt eine Liste von Aktionen aus. Dann bildet sequence_
eine Sequenz aus dieser Liste von Aktionen.sequence_ ist noch
anzumerken, dass das "_" in "sequence_" darauf
hinweist, dass die Ergebnisse der Sub-Aktionen weggeworfen werden und
nur () ausgegeben wird (d.h. die Ergebnisse sind in dieser Funktion nicht
relevant). sequence_ hat eine verwandte Funktion sequence,
die eine Liste von Aktionen nimmt und dabei die einzelnen (Sub-)Ergebnisse
vom Typ a liefert und diese als eine Komponente vom Typ
[a] zurück gibt:sequence :: [IO a] -> IO [a]sequence [] = return []sequence (a:as) = do { r <- a ;
rs <- sequence as ;
return (r:rs) } IORefs
umgesetzt wurden (MVars sind eine synchronisierte
Form von IORefs und werden im Abschnitt Concurrency behandelt):data IORef a
-- An abstract typenewIORef :: a -> IO (IORef a)readIORef :: IORef a -> IO awriteIORef :: IORef a -> a -> IO ()IORef a ist eine Referenz, die auf eine variable
(engl.: mutable) Speicherstelle verweist in der ein Wert vom Typ a
enthalten ist. Mit newIORef kann eine neue
Speicherstelle (Variable) mit einem initialen Wert erstellt werden.
Diese Speicherstelle (Variable) kann mit readIORef
bzw. writeIORef gelesen bzw. beschrieben
werden.IORef wird oft dazu benutzt den Zustand eines
externen Objektes (Objekt von Aussenwelt) zu erfassen bzw. zu verfolgen.
Hierzu bietet Haskell98 folgende Funktionen zum Öffnen, Lesen und
Schreiben von Dateien:openFile :: String -> IOMode -> IO HandlehPutStr :: Handle -> [Char] -> IO ()hGetLine :: Handle -> IO [Char]hClose :: Handle -> IO ()Chars)
aus einer Datei gelesen bzw. in eine Datei geschrieben worden sind, kann
man das dadurch erreichen, indem man hPutStr und
hGetLine eine Variable (IORef) inkrementieren
lässt. Dazu braucht man ein modifiziertes Handle:type HandleC = (Handle, IORef Int)openFile
erzeugen die eine Variable beim Öffnen einer Datei erstellt
und ein HandleC zurück gibt. Dann können
hPutStr und hGetLine in
modifizierter Form dieses HandleC nehmen und
die Variable (IORef) entsprechend verändern.openFileC :: String -> IOMode -> IO HandleCopenFileC fn mode = do { h <- openFile fn mode ;
v <- newIORef 0 ;
return (h,v) }hPutStr :: HandleC -> String -> IO ()hPutStr (h,r) cs = do { v <- readIORef r ;
writeIORef r (v + length cs) ;
hPutStr h cs }(>>=)) liefern
eine IO Aktion aus, aber nehmen keine als Argument.(>>=) kombiniert IO Aktionen
zusammen. unsafePerformIO :: IO a -> aconfigFileContents :: [String]configFileContents = lines (unsafePerformIO (readFile "config"))forkIO, die neue Threads erzeugt.acceptConnections :: Config -> Socket -> IO ()acceptConnections config socket = forever ( do { conn <- accept
socket ;
forkIO (serviceConn config conn)
} )accept endlos vom Eltern-Thread aufgerufen
und für jeden eingehenden Request ein neuer Thread erzeugt,
der diesen dann bearbeitet. accept gibt ein Handle
zurück, mit dem der Server mit dem Client kommunizieren kann.accept :: Socket -> IOConnectiontype Connection = ( Handle, SockAddr )forkIO :: IO a -> IOThreadId(serviceConn config conn) und läuft dann
parallel zum Eltern-Thread. forkIO gibt einen Identifier (ThreadId)
des neuen Threads zurück (siehe asynchrone Exceptions -> Fehlererkennung).forkIO kann aber (wie unsafePerformIO)
gefährlich sein, weil zwei oder mehrere Threads gleiche Aktionen
(z.B. Ausgabe am Bildschirm / Datei lesen/schreiben, etc.) zur gleichen
Zeit ausführen können.MVar realisiert
wurde. MVar ist hierbei eine synchronisierte Version
von IORef, d.h. eine synchronisierte Referenz auf eine Variable
die nur von einem Thread zur gleichen Zeit in-/dekrementiert werden kann.
Die Funktionsweise ist wie bei Semaphoren: will ein Thread eine Ressource
schreiben (lesen) wird die Ressource vor Zugriff anderer Threads blockiert,
bis dieser Thread die Ressource wieder freigibt.data MVar anewEmptyMVar :: IO (MVar a)takeMVar :: MVar a -> IO aputMVar :: MVar a -> a -> IO ()newEmptyMVar kann man ein MVar
erzeugen, wobei dieses leer ist (im Gegensatz zu IORef). takeMVar
holt (liest) den Wert aus der MVar heraus und macht
es leer. putMVar fügt einen Wert (schreibt) in die MVar
ein. Wenn die erzeugte MVar leer ist, wird takeMVar
solange blockiert bis ein Wert mit putMVar eingefügt
wurde.count) in der Server SchleifeacceptConnections :: Config -> Socket -> IO ()acceptConnections config socket = do { count <- newEmptyMVar
;
putMVar count 0 ;
forever ( do { conn <- accept socket
forkIO ( do { inc
count ;
serviceConn config conn;
dec count } )
} ) }
inc,dec :: MVar
Int -> IO ()
inc count =
do { v <- takeMVar count; putMvar count (v+1) }
dec count =
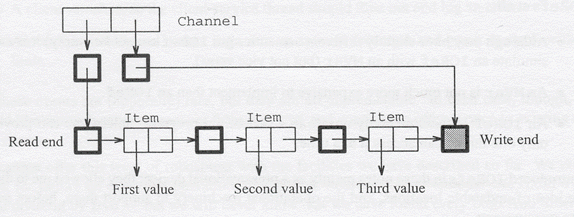
do { v <- takeMVar count; putMVar count (v-1) }Channel implementiert, das mehreren
Threads erlaubt darin reinzuschreiben bzw. daraus herauszulesen:type Channel a = ( MVar (Stream a) -- Read end
MVar (Stream a) ) -- Write end (hole: empty MVar = end of
Channel)newChan :: IO (Channel a)putChan :: Channel a -> a -> IO ()getChan :: Channel a -> IO a
Channel wird als ein Paar von MVars definiert
(MVars mit dickeren Rändern gekennzeichnet), die das Lese-Ende
(read end) und Schreib-Ende (write end) eines Channels
bilden. Um das Schreiben/Lesen mehrerer Threads zu ermöglichen, gibt
es zwischen jedem Wert (das in einem Item steht) ein MVar
das nur den jeweiligen Wert (ent)blockiert und nicht den ganzen Channel.type Stream a = MVar (Item a)data Item a = MkItem a (Stream a)newChan = do { read <- newEmptyMVar ; write <-
newEmptyMVar ; hole <-
newEmptyMVar; putMVar
read hole ; putMVar
write hole ; return
(read,write) }putChan (read,write) val = do { new_hole <- newEmptyMVar ;
old_hole <- takeMVar
write ;
putMVar write new_hole ;
putMVar old_hole (MkItem
val new_hole) }getChan (read,write) = do { head_var <- takeMVar read ;
MkItem val new_head <- takeMVar head_var
;
putMVar read new_head ;
return val }Item besteht aus dem ersten Element eines Streams
und den Rest des Streams. Stream ist
eine Liste von alternierenden Item und MVars,
die mit einem leeren MVar (hole) endet. Das
Schreib-Ende (write end) vom Channel (ein MVar)
verweist auf dieses "hole".Channel
nur ein "read" und ein "write" MVar,
als auch ein (leeres) MVar für den Stream
selbst.Channel reinschreiben zu können, muss
man einen neuen, leeren Stream (new_hole)
erzeugen und anschliessend das neue mit dem vorhandenen (old_hole)
ersetzen. Abschliessend, muss man nur noch ein Item in
das old_hole einsetzen, womit es vom hole
zum Item geworden ist. Anders ausgedrückt: Man erweitert
den Channel mit einem neuen hole und
fügt ein Item ins old_hole ein,
d.h. transformiert es zum Item.Channel funktioniert nach gleichem
Prinzip: Erzeugen von neuen Item (neues "read end")
und ersetzen durch nachfolgendes Item. Es ist aber zu beachten,
dass beim zweiten Aufruf von takeMVar (2.Zeile von getChan) getChan
blockieren kann, wenn der Channel leer ist (bis es wieder
aufgefüllt wurde durch einen anderen Thread).Channel, ist ein sicheres
Lesen/Schreiben von mehreren Threads zur gleichen Zeit gewährleistet.
Die Werte werden nach der Ankunftsreihenfolge der Threads in den Channel
reingeschrieben und jeder Wert wird von jeweils einem Thread rausgelesen.dubChan :: Channel a -> IO (Channel a)dubChan (read,write) = do { new_read <- newEmptyMVar ;
hole <- readMVar write ;
putMVar new_read hole ;
return (new_read, write) }readMVar :: MVar a -> IO areadMVar var = do { val <- takeMVar var ;
putMVar var val ;
return val ;
userError :: String -> IOErrorioError :: IOError -> IO acatch :: IO a -> (IOError -> IO a) -> IO
aioError mit dem Argument IOError
aufruft. Mit userError kann man einen IOError
aus einem String erstellen und mit catch
kann man eine Exception auffangen.(catch a h) ist eine Aktion,
die versucht die Aktion a auszuführen um anschliessend
ein Ergebnis zu liefern. Wenn aber a eine Exception
auslöst, dann wird a abgebrochen und stattdessen
(h e) zurückgegeben, wobei e der IOError
in der Exception ist.acceptConnections :: Config -> Socket -> IO ()acceptConnections config socket = forever ( do { conn <- accept
socket ;
forkIO (service conn) } )
where
service
:: Connection -> IO ()
service
conn = catch (serviceConn config conn)
(handler
conn)
handler
:: Connection -> Exception -> IO ()
handler
conn e = do { logError config e ;
hClose
(fst conn) }(service conn) hat hier einen
Exception Handler, so dass im Falle einer ausgelösten Exception
der handler aktiv wird. Der handler
schreibt den Fehler in die Log Datei (durch senden einer Nachricht zum
error-logging Thread über einen Kanal (engl.: channel)) und schliesst
den Verbindungshandler h.throw es 1 + throw ex2, hängt von der Reihenfolge
der Auswertung ab. throw e aussergewöhnliche
Werte (engl.: exceptional values) zurück gibt (bei IEEE sind
NaN: "not-a-numbers" und NaT: "not-a-thing" für Hardware definiert).
Und welche Exception ausgelöst wird (bei mehreren Exceptions),
hängt letztendlich vom Compiler ab (s. lazy evaluation in Haskell).throwTo :: ThreadId -> Exception -> IO ()ThreadId braucht. Die ThreadId
wird von forkIO geliefert, so dass eigentlich nur der
ElternThread das Kind unterbrechen kann, es sei denn es gibt die ThreadId
des Kindes an andere Threads weiter.throwTo:parIO :: IO a -> IO a -> IO aparIO a1 a2 = do { m <- newEmptyMVar ;
c1 <- forkIO (child m a1) ;
c2 <- forkIO (child m a2) ;
r <- takeMVar m ;
throwTo c1 Kill ;
throwTo c2 Kill ;
return r } where child
m a = do { r <- a ; putMVar m r }parIO lässt zwei Threads mit jeweils einer separaten
Aktion seiner Argumente gleichzeitig laufen und wartet bis einer der beiden
zuerst fertig wird. Wenn ein Thread fertig ist, wird der andere Thread von parIO
durch ein Kill Signal beendet.parIO ein einfaches timeout
implementieren:timeout :: Int -> IO a -> IO (Maybe a)timeout n a = parIO ( do { r <- a ; return (Just r) } )
( do { threadDelay n ; return Nothing } )(timeout n a) liefert Nothing zurück,
wenn die Aktion a länger als n Mikrosekunden
dauert, ansonsten gibt es Just r zurück, wobei r
der von a gelieferteWert ist.catch Handler springt. Um den bestimmten Thread aber zu beenden,
ist eine entsprechende Modifizierung von parIO notwendig.
... [
Informatik und Master-Seminar SS2003 ] ... [ HWS
Gesamtübersicht ] ... [ Haskell
Erweiterungsanforderungen ] ... [ Web
Server Implementierung ] ...