Von
Oliver R. Ahlemann
Mi7672
Letztenendes ist das Signal nun eine Folge von Einsen und Nullen. Genaueres folgt im jetzigen Kapitel.
Es gibt verschiedene Kodierungsmöglichkeiten.
Das wichtigste ist PCM (Pulse code modulation), es wurde oben beschrieben. Die Digitaldaten sind hierbei direkte äquivalente Werte des Analogsignals. Also auch negative Signale, die in der digitalen Welt als 2er-Komplement dargestellt werden. Es gibt Verfahren, welche darauf aufbauen und die Datenmenge verlustfrei verringern können.
Hierbei wird nicht das Signal codiert, sondern die Differenz zur vorherigen Abtastung. Da meistens die Unterschiede von nebeneinanderliegenden Tönen sehr gering sind, kann man so die Auflösung herunterschrauben, ohne Datenverlust.
Dieses Verfahren wurde noch mal verbessert, indem ein Prediktionswert eingeführt wurde. Dieser Wert ist eine Vermutung, wie das nächste Signal aussehen könnte. Es wird immer wieder neu aus der Reihe der vorherigen Muster errechnet. Nun wird nur die Differenz zuwischen dem tatsächlichen Wert und der Voraussage codiert.
Von Kompression spricht man, wenn der Informationsgehalt nach Codieren und Decodieren vollständig erhalten bleibt
Viele Daten bestehen aus Folgen identischer Bytes. Ist deren Anzahl groß, so kann eine erhebliche Reduktion der Datenmenge erreicht werden, indem die entsprechende Anzahl sich wiederholender Bytes angegeben wird. Hierzu ist eine spezielle Markierung M innerhalb der Daten notwendig, die selbst nicht als Datenbestandteil auftritt. Als Erläuterung für ein solches Byte-Stuffing sei als M-Byte das Ausrufezeichen definiert. Hiermit kann der Beginn einer solchen Lauflängenkodierung markiert werden. Wenn nun ein Byte mindestens viermal in Folge auftritt, dann wird begonnen, das Vorkommen zu zählen. Die komprimierten Daten beinhalten dieses Byte, gefolgt vom M-Byte und der Anzahl des Auftretens des Zeichens. So lassen sich immer mindestens 4 und höchstens 259 gleiche Bytes zu 3 Byte zusammenfassen.
Im folgenden Beispiel tritt das Zeichen "c" achtmal hintereinander auf und wird zu den drei Zeichen "c!8" komprimiert:
Unkomprimierte Daten: ABCCCCCCCCDEFGGG
Komprimierte Daten: ABC!8DEFGGG
Anstatt einzelne Bytes oder Bytefolgen zu komprimieren, kann auch eine Differenzkodierung von Bytes und Bytefolgen vorgenommen werden. Ist beispielsweise eine Folge von Zeichen deutlich von Null verschieden, jedoch nicht stark voneinander abweichend, so kann die Bildung der jeweiligen Differenz zum vorherigen Wert Vorteile bei der Kodierung bringen. s.DPCM
Bei Huffman ist die Häufigkeit bestimmter Werte entscheidend. Häufig auftauchende Werte erhalten eine kurze Bitfolge, selten auftretende Werte hingegen eine lange. Daher ermittelt der Algorithmus zunächst die Verteilung der Werte innerhalb der zu komprimierenden Daten. Um einen sogenannten Huffman-Baum zu ermitteln, beginnt man mit den beiden seltensten Werten. Ihnen wird eine "0" beziehungsweise eine "1" zugewiesen. Es erfolgt eine Zusammenfassung der beiden Werte, in der Reihenfolge sind sie nun durch die Summe ihrer Häufigkeit repräsentiert. Das gleiche geschieht mit den nächsten beiden seltensten Werten. Dieser Vorgang ist beendet, wenn nur noch ein Wert übrig ist. Das Ergebnis dieser Vorgehensweise ist eine Baumstruktur. Anhand dieser Struktur erfolgt die Kodierung. Jede Verzweigung nach links erhält eine 0, jede Rechtsverzweigung ist durch eine "1" gekennzeichnet.
Von Datenreduktion spricht man, wenn der Informationsgehalt verringert wird und sich nach der Decodierung auch nicht wieder exakt rekonstruieren lässt.
Es gibt zwei Ansätze zur verlustbehafteten Datenreduktion: Redundanzreduktion und Irrelevanzreduktion.
Die Redundanz ist ein Maß für die Menge an Daten, die man braucht, um eine Information speicher-effizient darzustellen.
Irrelevanz ist die Menge an Daten, die man weglassen kann, ohne die Information wahrnehmbar zu verzerren.
Es ist einleuchtend, dass der Kompressionsfaktor vom zu komprimierenden Audiosignal abhängt. Deshalb sind diese Verfahren für die Datenübertragung nur bedingt geeignet, da hier der schwankenden Kompressionsrate eine konstante Übertragungsbandbreite gegenübersteht. Die Verringerung der Redundanz allein reicht also nicht aus. Daher versucht man auch die Irrelevanz von Daten zu nutzen, indem Informationen, die vom Gehör unter bestimmten Umständen nicht wahrgenommen werden, einfach weggelassen werden.
Das Gebiet der Psychoakustik beschreibt, wie das menschliche Gehör die Lautheit von Tönen empfindet, was durch Hörtests ermittelt werden kann. Das Gehör reagiert auf Frequenzen zwischen 20 Hz und 20 kHz, am empfindlichsten ist es zwischen 2 und 4 kHz. Für die Bewertung der Leistung eines Audiokodierers, der psychoakustische Phänomene ausnutzt ("Perceptual Audio Coder"), existieren bisher keine technischen Verfahren, deshalb werden Hörtests mit geschulten Testpersonen durchgeführt.
Man nutzt einige Schwächen des menschlichen Gehörs aus, um dem Hörer gezielt bestimmte Frequenzanteile vorzuenthalten, die er ohnehin nicht wahrnehmen würde. Diesen Effekt nennt man Verdeckung oder Maskierung.
Im täglichen Leben spielt Maskierung eine wichtige Rolle. Man stelle sich vor, man unterhält sich mit jemandem und alles um einen herum ist ruhig. Man spricht in einer "normalen" Lautstärke. Fliegt nun ein Flugzeug in der Nähe vorbei, ändert sich die Situation für das Gehör. Redet man mit gleicher Lautstärke weiter, kann einen der andere nicht mehr verstehen. Das Störgeräusch überdeckt den Sprachschall. Dieses Phänomen nennt man Maskierung (Überdeckung).
Töne müssen eine Mindestlautstärke haben, um von einem Hörer wahrgenommen zu werden. Diese Mindestlautstärke ist abhängig von der Frequenz des Tons. Spielt man einer Testperson Töne verschiedener Frequenz vor, deren Lautstärke man erhöht, bis sie gerade wahrgenommen werden, erhält man folgendes Diagramm:
Abbildung 10: Hörschwelle
Die wichtigsten Effekte, die bei der verlustbehafteten Audiocodierung zum Tragen kommen, sind die simultane und die temporale Maskierung.
Die simultane Maskierung tritt bei zwei oder mehreren Signalen unterschiedlicher Frequenz auf, die gleichzeitig im Innenohr eintreffen. Das Prinzip: Durch die Präsenz eines Signals wird die Ruhehörschwelle modifiziert, da das Gehör in der Umgebung dieser Frequenzkomponente weniger empfindlich wird, eine neue Hörempfindlichkeitskurve entsteht: die Mithörschwelle. Fällt nun ein zweites Signal, das für sich allein die Ruhehörschwelle übersteigen würde und daher durchaus hörbar wäre, unter diese Mithörschwelle, wird sie von der starken ersten Frequenzkomponente maskiert und ist nicht mehr wahrnehmbar. Beispiel: Man hört einen leisen Ton mit 1,1 kHz nicht, wenn gleichzeitig ein lauter Ton mit 1 kHz gespielt wird. Mehr noch: Wenn sonst Stille ist, hört man selbst einen sehr leisen Ton von 1 kHz sofort, während ein Ton von 100 Hz bei selber Lautstärke evtl. nicht wahrnehmbar ist. Fügt man nun einen (recht lauten) Sinuston mit 1 kHz ein, ändert sich die Hörschwelle drastisch:
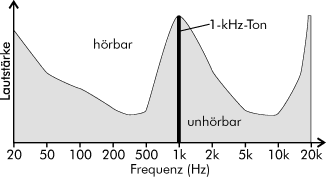
Abbildung 11: Hörschwelle bei 1kHz Sinuston
Es ist also ein riesiger maskierter Bereich entstanden, der nicht übertragen werden muss, weil man ihn nicht hören kann. Liegt also noch ein 2 kHz Signal mit einer Lautstärke von etwa einem Drittel auf der Skala des Diagramms an, könnte (und würde) der typische Perceptual Audio Coder dieses Signal einfach ignorieren. Mit zunehmender Frequenz des Maskierungstons wird der maskierte Frequenzbereich breiter. Die Breite dieser sogenannten "kritischen Frequenzbänder" liegt zwischen unter 100 Hz für die tiefsten wahrnehmbaren Töne und über 4 kHz für die höchsten. Der Grad der Maskierung einer bestimmten Frequenz ist lediglich abhängig von der Signalintensität im kritischen Band dieser Frequenz. Der vom Gehör wahrnehmbare Frequenzbereich läßt sich in 27 kritische Bänder unterteilen.
Abbildung 12: Kritische Frequenzbänder
Die zweite Art der Verdeckung, die temporale Maskierung, manifestiert sich bei sich schnell ändernden Signalen. Tritt ein Schallereignis ("Gauß-Impuls") plötzlich auf und endet auch nach einer bestimmten Zeit wieder, so braucht das Gehör eine gewisse Erholungszeit, bis es wieder die volle Empfindlichkeit aufweist. Diesen Effekt nennt man zeitliche Nachverdeckung. Interessanterweise kann man auch keine Töne wahrnehmen, die kurz vor dem Gauß-Impuls liegen (zeitliche Vorverdeckung):
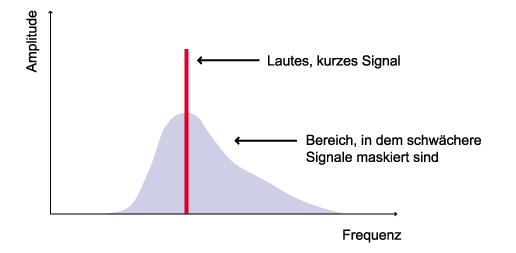
Abbildung 13: Hörschwelle bei Gauß-Impuls
Wohl jeder, der mal an einem PC gesessen hat, kennt das WAV-Format. WAV ist der größte gemeinsame Nenner der Windows Audioformate. Dieses Format wurde ursprünglich von Microsoft und IBM in den 80er Jahren entwickelt und diente als binäre Audiodatei. Es ist sozusagen eine "digitale Kopie" des Schalldrucks am Mikrofon während der Tonaufnahme.
Im allgemeinen wird erwartet, dass eine Wav-Datei nur unkommentierte Daten im PCM-Format enthält. Die Daten werden in Pakete aufgeteilt, die sowohl die Trennung der Kanäle als auch in LSBs (Least Significant Bit)und MSBs (Most Significant Bit) vornehmen. Über die Formate der Speicherung haben wir ja schon gesprochen (PCM, DPCM,...) Grob gesehen besteht das WAV-Format aus mindestens 2 Chunks, einem Format und einem Data-Chunk. Falls nicht PCM benutzt wurde, kann auch noch ein FACT-Chunk angehängt sein, welches Angaben zum verwendeten Aufzeichnungsformat macht.
FMT, DATA, (FACT)
| Byte | Hex | Bedeutung | Bemerkung |
| 00 - 03 | 52, 49, 46, 46 | `RIFF` | WAV - Kennung |
| 04 | - | Dateilänge - 8 | Byte 0 |
| 05 | - | Dateilänge - 8 | Byte 1 |
| 06 | - | Dateilänge - 8 | Byte 2 |
| 07 | - | Dateilänge - 8 | Byte 3 |
| 08 - 0E | 57, 41, 56, 45, 66, 6D, 74 | "WAVEfmt" | WAV - Kennung |
| 0F | 20 | Blank | - |
| 10 | 10 | Länge des nächsten Blocks | Byte 0 |
| 11 | 00 | Byte 1 | |
| 12 | 00 | Byte 2 | |
| 13 | 00 | Byte 3 | |
| 14 | 01 | Formattyp | LSB |
| 15 | 00 | Formattyp | MSB |
| 16 | - | Anzahl der Kanäle | LSB |
| 17 | - | Anzahl der Kanäle | MSB |
| 18 | - | Einfache Sampleclock | Byte 0 |
| 19 | - | Einfache Sampleclock | Byte 1 |
| 1A | - | Einfache Sampleclock | Byte 2 |
| 1B | - | Einfache Sampleclock | Byte 3 |
| 1C | - | Gesamt-Sampleclock | Byte 0 |
| 1D | - | Gesamt-Sampleclock | Byte 1 |
| 1E | - | Gesamt-Sampleclock | Byte 2 |
| 1F | - | Gesamt-Sampleclock | Byte 3 |
| 20 | - | Gesamtdatenbytes/Sample | LSB |
| 21 | - | Gesamtdatenbytes/Sample | MSB |
| 22 | - | Auflösung/Sample | LSB |
| 23 | - | Auflösung/Sample | MSB |
| 24 - 27 | 64, 61, 74, 61 | `data` | Kennung für Datenanfang |
| 28 | - | Gesamtanz. Datenbytes | Byte 0 |
| 29 | - | Gesamtanz. Datenbytes | Byte 1 |
| 2A | - | Gesamtanz. Datenbytes | Byte 2 |
| 2B | - | Gesamtanz. Datenbytes | Byte 3 |
| 2C | - | Erstes Datenbyte | LSB bei 16-Bit Auflösung |
Tabelle 2: Header einer WAVE-Datei
Der Header besteht meist aus 44 Bytes, dahinter schließen sich gleich die Daten an. Hier ist zu berücksichtigen, dass auch im Datenbereich bei 16-Bit-Auflösung zunächst LSB, dann MSB erscheint. Bei Stereodateien alternieren ständig die Daten für den linken und den rechten Kanal, wobei links begonnen wird.
AIFF ist ein Dateiformat für Audio-Files, das von Apple entwickelt wurde und auf dem EA IFF 85 Standard von Electronic Arts basiert. Es enthält neben den unkomprimierten Audio-Daten Informationen über die Anzahl der Kanäle (mono oder stereo), die Anzahl der Bits (8 oder 16), die Sample-Rate (z.B. 44.1kHz) und applikationsspezifische Datenteile. Das AIFF-Format ist das gängigste Format auf der Apple-Plattform.
Das AU Format ist das Standard Unix-Format für Audiodaten, auch bekannt als Sun/NeXT Format, weil es von diesen beiden Firmen entwickelt wurde. Es beherrscht neben dem linearen Sampling wie bei WAVE oder AIFF Dateien auch das logarithmische Sampling, d.h. ein Sampling mit einer Abtastrate von 16 Bit wird in nur 8 Bit gespeichert. Das Ergebnis gleicht dann qualitativ ungefähr einem linearen 12 Bit Sampling.
Die Kompressionsverfahren arbeiten wie gesagt nicht verlustfrei, d.h. das Originalsignal kann nach der Kompression nicht genau rekonstruiert werden. Um die hohen Kompressionsraten zu erzielen, arbeitet der Kodierer im Frequenzbereich und entfernt die Signalkomponenten, die vom menschlichen Gehör nicht wahrgenommen werden können.
MP3 ist genauer gesagt MPEG 1 Layer 3. Dieses Verfahren wurde von der Motion Picture Experts Group spezifiziert. Der Layer III Algorithmus ist ein ISO-Standart und wurde maßgeblich am Frauenhofer Institut für integrierte Schaltungen entwickelt. In dem ISO-Standard sind nur der Dekodierer und das Datenformat spezifiziert. Der Kodierer nicht! Dadurch ist es möglich effizientere Kodierer zu entwickeln, die immer noch kompatibel sind. Die Kodierung in MP3 läuft in etwa fogendermaßen ab:
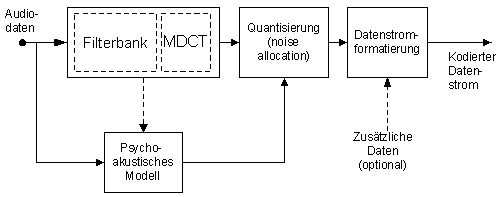
Abbildung 14: Schema MP3 Codierung
Die Filterbank transformiert das zu kodierende Audiosignal vom Zeit- in den Frequenzbereich, wobei es in 32 Frequenzbänder (Subbänder) gleicher Breite unterteilt wird, welche die kritischen Bänder approximieren sollen. Für 32 eingelesene Samples wird pro Subband ein Sample ausgegeben. Eine unerwünschte Eigenschaft der Filterbank ist das sogenannte "Aliasing": Die 32 Subbänder überlappen sich, und so kann ein Ton einer festen Frequenz zwei Bänder beeinflussen. Die Subbänder werden durch eine modifizierte diskrete Cosinus-Transformation (MDCT) jeweils nochmals in 18 Teilbereiche unterteilt. Dadurch ergibt sich eine höhere Spektralauflösung, außerdem ist es nun möglich, den Aliasingeffekt teilweise zu entfernen.
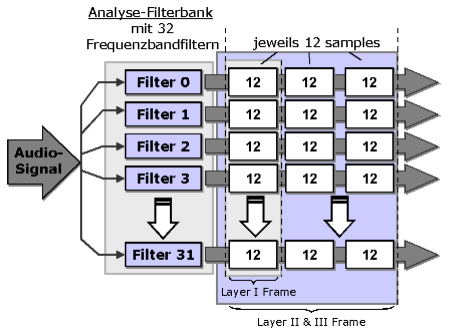
Abbildung 15: Filterbank
Das prinzipielle Verfahren des Quantisierers ist folgendes:
Wenn die Signalintensität eines Subbandes unter dessen Maskierung liegt, muß das Signal gar nicht kodiert werden, weil es unhörbar bleibt. Ansonsten werden die Frequenzsamples mit gerade so vielen Bits quantisiert, daß das dadurch eingeführte Quantisierungsrauschen durch die Maskierung gerade noch unhörbar bleibt. Für jede Gruppe von 3x12 Samples eines Subbandes gibt es einen Wert, der angibt, mit wie vielen Bits Auflösung diese Samples quantisiert werden und bis zu drei Skalierungsfaktoren (höchstens einer für 12 Samples). Die Skalierungsfaktoren werden bei der Dekodierung mit den quantisierten Samples multipliziert, wodurch sich eine Verbesserung der Quantisierungsauflösung ergeben kann. Drei Skalierungsfaktoren pro Block werden nur verwendet, wenn es unbedingt nötig ist, um Verzerrungen des Signals zu vermeiden. Skalierungsfaktoren werden von zwei oder allen drei 12er-Gruppen gemeinsam genutzt wenn:
(1) sich die Werte der Skalierungsfaktoren ähnlich genug sind, oder
(2) wenn der Kodierer erkennt, daß die zeitliche Maskierung des Gehörs die eingeführten Fehler unhörbar macht.
Es wird eine Iterationsschleife durchlaufen, die Quantisierungsparameter in geordneter Weise variiert, die Samples quantisiert und das dadurch erzeugte Quantisierungsrauschen tatsächlich ausrechnet, um zu prüfen, ob es im unhörbaren Bereich bleibt. Wenn dies nicht der Fall ist, wird für die entsprechenden Subbänder eine feinere Quantisierung gewählt ("noise allocation"). Diese Schleife benötigt den Hauptteil der Rechenzeit beim Quantisierungsprozeß. Außerdem werden die quantisierten Samples zusätzlich Huffman-kodiert, um eine weitere Reduzierung des Speicherbedarfs zu erzielen. Die verwendeten Huffman-Bäume sind statisch. Für ein Audiosignal, das mit einer Abtastfrequenz von 44,1 kHz aufgezeichnet wurde und durch Kompression auf eine Datenrate von 128 kBit/s reduziert werden soll, ergibt sich pro Datenblock eine Größe von:
1152 (Samples/Block) x 128000 (Bits/s) / 44100 (Samples/s) = 3344 (Bits/Block)
Benötigt ein Block weniger als die diese Anzahl an Bits, so werden die übrigen Bits an das sogenannte "Bit-Reservoir" übergeben. Läßt sich umgekehrt ein Block nicht ohne hörbaren Qualitätsverlust mit der vorgegebenen Blockgröße kodieren, so können Bits aus dem Bit-Reservoir entnommen werden, die zusätzlich zur Kodierung des Blocks verwendet werden. Die Blöcke, die nicht die ganze Blockgröße benötigen, werden mit Daten der nächsten Blöcke aufgefüllt; siehe Bild 8. Es dürfen jedoch zu keiner Zeit mehr Bits entnommen werden als im Bit-Reservoir vorhanden sind.
MP3 hat ein Kompressionsverhältnis von 10:1 bis 12:1 und übliche Datenraten von 128 bis 112 kBit/s.
AAC wurde im Rahmen der MPEG-Architektur unter maßgeblicher Beteiligung der Fraunhofer-Gesellschaft entwickelt und standardisiert. Dieses Verfahren erreicht selbst bei einem Reduktionsfaktor von 16 noch CD-ähnliche Qualität und unterstützt bis zu 48 Tonkanäle. Schon bei einer Bitrate von 64 KBit/s ist Advanced Audio Coding anderen Formaten deutlich überlegen. Bei 320 KBit/s wird eine exzellente Qualität erreicht. Mit dem Advanced Audio Coder ist von dem Konzept der Hybrid-Filterbank abgewichen worden. Der AAC setzt ausschließlich eine MDCT ("Modified Discrete Cosine Transformation") mit zwei verschiedenen Blocklängen ein. Bei "long blocks" werden 2048 Samples, bei "short blocks" 256 Samples verarbeitet, wodurch gegenüber MP3 sowohl eine höhere Frequenz- als auch Zeitauflösung erreicht wird. Der "Joint Stereo"-Mode ist gegenüber MP3 flexibler, da er unabhängig für Frequenzbereiche geschaltet werden kann und nicht, wie bei MP3, für den gesamten Frequenzbereich. Der AAC-Encoder besitzt außerdem einige Tools, wie z.B. LTP (long term prediction), PNS (perceptual noise substitution) und TNS (temporal noise shaping), die die Bitrate weiter absenken können. AAC ist auch ein Teil des neuen Standards MPEG-4 und wird vermutlich in vielfältigen Anwendungen wiederzufinden sein. In Japan hat man sich bereits entschieden, AAC als Tonverfahren für das digitale hochauflösende Fernsehen (HDTV, High Definition Television) zu verwenden. In den USA setzt die Mehrheit der Bewerber für das digitale Radio (IBOC, In Band on Channel) auf AAC. Nach dem Willen der Hersteller soll AAC der neue Standard im Netz werden und MP3 ablösen.
Das Real Audio Format wurde von Real Networks entwickelt und ermöglicht Streaming Audio, d.h. die Wiedergabe startet sofort nach Aufruf der Datei. Möglich wird dies durch eine geringe Datenrate und einer Übertragung über das Internet mit dem UDP (User Datagram Protocol). Jedes UDP Datenpaket enthält einen Teil der Audiodaten der letzten 4 Sekunden. Der Verlust eines Datenpaketes führt daher nicht zu Unterbrechungen der Audiowiedergabe. So entgeht Real auch weitgehend dem Copyright-Problem: Da man sich Stücke in der Regel nur anhören, sie aber nicht speichern kann, können sie auch nicht vervielfältig werden. Nur hartnäckige Nutzer machen sich die Mühe, den Datenstrom abzufangen und zu speichern. Die Klangqualität von Real Audio hängt stark von der zur Verfügung stehenden Bandbreite ab. Ein Analog-Modem erreicht nur Radio-Qualität - Störungen inklusive. Mit einem DSL-Zugang schafft Real Audio aber durchaus CD-Qualität. Über das Codierverfahren gibt Real Networks keine Auskunft, die geringe Datenrate wird aber nicht durch komplexe Datenreduktionsalgorithmen sondern durch Verzicht auf Audioqualität erreicht. Bei stark datenreduzierten Signalen würde der Verlust von Datenpaketen die Audiowiedergabe stark verschlechtern, daher ist eine komplexe Reduktion nicht möglich. Den Vorteil der sofortigen Wiedergabe ohne vorherigen Download der Audiodatei erkauft man sich also mit einer etwas schlechteren Audioqualität bei der Wiedergabe.
Anfang 1999 besann sich Microsoft darauf, dass auch der Audio-Markt nicht uninteressant ist und entwickelte ein eigenes Format, MS-Audio. Später wurde es dann in WMA umbenannt. Microsofts entscheidendes Argument neben einer besseren Klangqualität war für kurze Zeit der Kopierschutz. Das integrierte Digital-Rights-Managements sollte das Kopieren von Dateien im WMA-Format verhindern. Innerhalb kürzester Zeit wurde dieser Mechanismus durch einen simplen Trick überlistet. Ein kleines Tool fängt den Datenstrom an der Soundkarte ab und ermöglicht die Speicherung in ein anderes Format. WMA ist streaming-fähig und daher interessant für Anwendungen wie Internet-Radio. Qualitativ ist WMA nicht unbedingt eine Offenbarung: Deutliche Artefakte sind zu hören. Selbst MP3-Files mit 64 KBit/s klingen teilweise besser. Dank Microsofts Monopolstellung ist die Unterstützung von WMA sowohl auf Hard- als auch Software-Seite sehr gut - dafür sorgt schon der Windows Media Player. Allerdings ist es schwierig, Lieder in diesem Format zu finden.
Vorbis Ogg Vorbis ist das einzige echte Open-Source-Format und bietet dazu noch gute Qualität. Das entscheidende Argument, welches die Entwickler von Ogg Vorbis für ihr Format - und unter anderem gegen MP3 - vorbringen, ist die Tatsache, dass Ogg Vorbis ein freies Format ist. Niemand kann Gebühren verlangen, auch nicht die Plattenindustrie. Technisch gesehen ist Ogg Vorbis Teil des Ogg-Projekts, in dessen Rahmen ein vollständig offenes Multimedia-System entwickelt werden soll. Ogg Vorbis ist der einzige Teil des Projekts, der bisher realisiert worden ist. Mit Ogg Vorbis lassen sich Audio-Dateien mit 44,1 bis 48 KHz und einer Bitrate von 16 bis 128 kbps erstellen. Wie MP3 ist Ogg Vorbis auch ein verlustbehaftetes Komprimierungsverfahren, allerdings sollen die verwendeten akustischen Modelle denen von MP3 deutlich überlegen sein. In der Tat bieten einige von der Ogg Vorbis Homepage heruntergeladene Songs bei Bitraten von 100 bis 128 KBit/s eine Klang-Qualität, die sich mit MP3 bei gleicher Bitrate durchaus messen kann. Die Dateigröße unterscheidet sich allerdings nicht nennenswert.
|
Format
|
Entwickler
|
Qualität
|
Perspektiven
|
|
MP3
|
Fraunhofer-Institut
|
bei 128 KBit/s akzeptabler Klang
|
Quasi-Standard im Internet
|
|
AAC
|
AT&T, Dolby Laboratories, FraunhoferIIS und Sony
|
schon bei 64 KBit/s anderen Formaten in der Qualität
deutlich überlegen
|
Favorit der Musikindustrie
|
|
RealAudio
|
Real
|
Qualität je nach Bandbreite
|
die Nr.1 für Streaming, für Download bedeutungslos
|
|
WMA
|
Microsoft
|
deutliche Artefakte
|
bisher kaum Interesse bei Anwendern und Musikindustrie
|
|
OggVorbis
|
Ogg-Projekt
|
bei 128 KBit/s vergleichbare Klangqualität wie MP3
|
einziges freies Format, dazu gute Qualität, bleibt
aber ähnlich wie Linux etwas für Freaks
|
Tabelle 3: Formate im Überblick