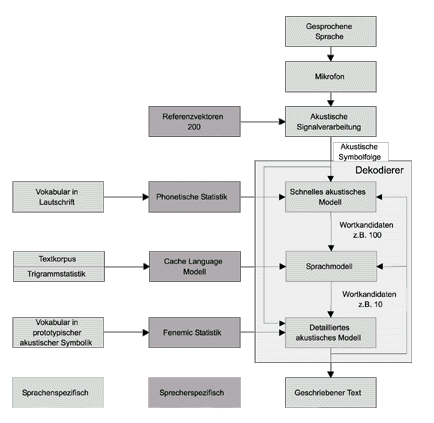
Zuerst erfolgt eine Digitalisierung der aufgenommenen Signale, die Gewinnung von spektralen Parametern aus der Fouriertransformation des digitalen Signals. Diese werden zu Merkmalsvektoren zusammengefasst (Vektorquantifizierung).
Danach erfolgt ein Vergleich des Merkmalsvektors und ein Ersetzen des Vektors durch das Symbol des ähnlichsten im System abgelegten Referenzvektors. Die Referenzvektoren werden in einer Trainingsphase sprecherspezifisch im System angelegt. Durch die Ersetzung der Vektoren durch die Symbole wird der Datenfluss im System stark reduziert.
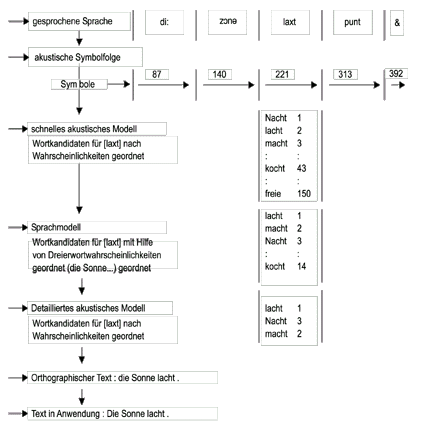
Ein schnelles akustisches Modell ermittelt aus dem Vokabular mehrere Wortkandidaten(etwa 100), die mit der größten Wahrscheinlichkeit zur akustischen Symbolfolge passen. Die Wahrscheinlichkeiten werden über HMM berechnet.
Dabei liegt das Vokabular in Lautschrift vor, als Folge von Allophonen. Jedem Allophon wird ein HMM zugeordnet, jedem Wort damit eine Folge von HMM. Die Wahrscheinlichkeits-Parameter der HMM werden in einer Trainingsphase an den Sprecher angepasst.
Ein komplexeres Sprachmodell schränkt die Anzahl der Wortkandidaten weiter ein. Die Auswahl geschieht hier in Abhängigkeit von der sprachlicher Umgebung, also der zwei vorangegangenen Worte (Trigrammstatistik).
Ein detailliertes akustisches Modell extrahiert vorläufige Endkandidaten. Dabei wird detaillierter die Wahrscheinlichkeit errechnet, dass Worte zu der akustischen Symbolfolge gehören. Der wahrscheinlichste Kandidat wird an einen Dekodierer weitergegeben, der die Symbolfolge in das entsprechende Wort umwandelt und das Wort dann als Text ausgibt.
Die Wahrscheinlichkeiten des detaillierten akustischen Modells ergeben sich aus HMM mit maschinell gewonnenen lautlichen Einheiten, die kürzer als Allophone sind. Sie entsprechen prototypischen akustischen Symbolen.
Die lautliche Darstellung der Einheiten wurde durch Vorsprechen mehrerer Sprecher abgebildet (sprecher-unabhängig). Die Wahrscheinlichkeits-Parameter der HMM aus dem benutzerspezifischem Training (sprecherabhängig).