Spracherkennungssysteme sind keine einheitlichen Systeme. Man kann Sie in verschiedene Kategorien einteilen.
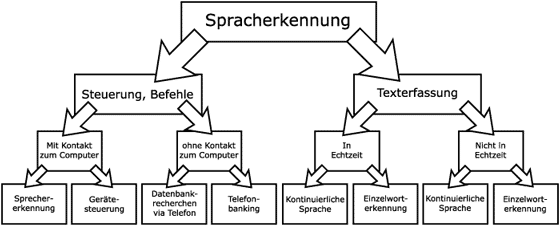
Steuerungssysteme verfügen nur über einen geringen Wortschatz, da meist nur wenige Befehle zur Steuerung nötig sind. Direkter Kontakt zum Gerät muss nicht unbedingt bestehen. Die Steuerung ist evtl. per Telefon möglich (Telefonbanking). Steuerungssysteme werden auch für Datenbankabfragen eingesetzt (Fahrplanauskunft der Deutschen Bahn per Telefon). Wird Spracherkennung nur zur Befehlseingabe verwendet, werden die gesprochenen Worte nicht in Text umgewandelt, sondern lediglich mit gespeicherten Mustern verglichen.
Sprachsteuerungen mit Kontakt zum Computer finden Anwendung bei Steuerungssystemen, die mittels sprachlich gegebener Befehle Geräte und Maschinen steuern.
Die gesprochenen Worte werden in Text umgewandelt. Die Systeme müssen dazu über einen großen Wortschatz verfügen, damit zufriedenstellende Ergebnisse erzielt werden.
Manche Systeme können in Echtzeit erfassen, andere mittels Stapel-Betrieb. Echtzeit Systeme können gesprochenen Text direkt ausgeben.
Ein weiteres Unterscheidungskriterium ist, ob diskrete oder (wie üblich) kontinuierliche gesprochene Sprache erkannt werden kann.
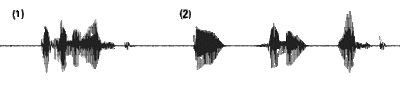
Die Abbildung zeigt die Wellendarstellung des gesprochenen Satzes "Die Sonne lacht". Unter (1) sieht man die Repräsentation für kontinuierlich gesprochene Sprache, unter (2) für diskret gesprochene.
Seit einigen Jahren existieren Systeme zur "isolierten Spracherkennung". Systeme mit begrenztem Wortschatz sind für den täglichen Einsatz nicht geeignet, da hier ein möglichst großes, auf den Kontext abgestimmtes Vokabular nötig ist, mit bis 60.000 Worte (mittlerweile mehr) bei Sprecher-Unabhängigkeit.
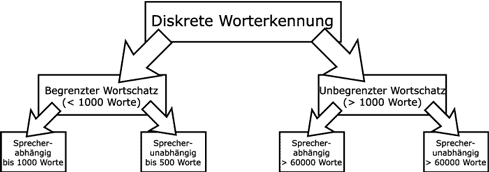
Bei kontinuierlicher Sprache sind die Worte ohne Pause aneinandergereiht. Für Menschen ist es kein Problem, die Worte auseinander zu nehmen. Für eine Maschine ist es um ein Vielfaches schwieriger, einen Redefluss zu strukturieren und in Worte zu zerlegen.
Das System muss dabei in Echtzeit entscheiden, an welcher Stelle Worte zu Ende sind.
Bei diskreter Erkennung ist schon ein hoher Rechenaufwand nötig, bei kontinuierlicher Erkennung ist der Aufwand noch wesentlicher höher. Besonders schwierig sind zusammengesetzte Worte (Bsp.: Mehrwert - mehr wert, radfahren - Rad fahren).
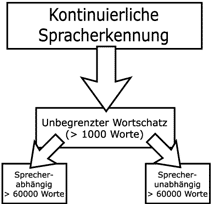
Durch die steigende Leistungsfähigkeit der Systeme gelingt die kontinuierliche Spracherkennung. Üblich sind für Sprecher-unabhängige Systeme mehr als 1.000.000 Worte.
Akustische Signale, die durch ein Mikrofon aufgenommen werden, müssen durch das Spracherkennungs-System so verarbeitet werden, dass als Ergebnis ein geschriebener Text vorliegt.
Die Verbindung von Akustik und Text wird durch ein Referenzmuster hergestellt. Dieses ist eine unteilbare Einheit, der ein Text zugeordnet ist, sozusagen eine "Schablone". Ein Spracherkennungs-System besitzt eine großen Vorrat an solchen Referenzmustern.
Eine Akustische Einheit kann ein Wort, eine Phrase oder ein ganzer Satz sein. Den Referenzmustern ist dann entsprechend ein Wort, eine Phrase oder ein Satz zugeordnet.
Wird jeder akustischen Einheit genau ein Referenzmuster zugeordnet, spricht man von diskreter Worterkennung.
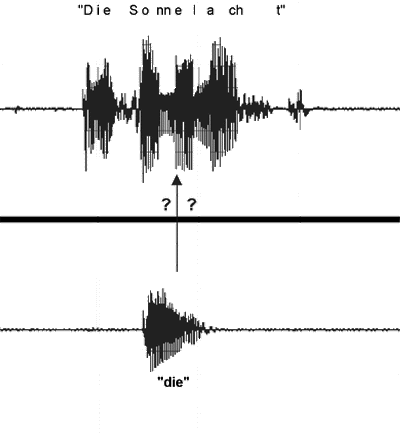
Die Abbildung zeigt, dass wenn nur das Wort "die" als Referenzmuster gespeichert ist, die Erkennung der akustischen Einheit "Die Sonne lacht" mittels diskreter Erkennung nicht möglich ist. Dazu müsste der komplette Satz als Referenzmuster hinterlegt sein.
Beziehen sich mehrere Referenzmuster auf eine akustische Einheit, spricht man von kontinuierlicher Spracherkennung.
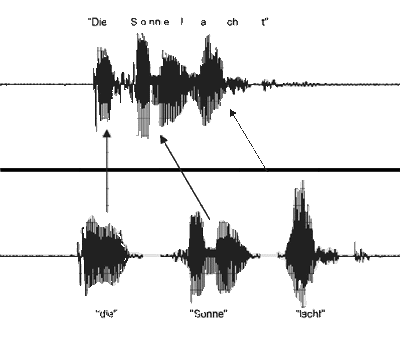
Die drei einzelnen Referenzmuster können der akustischen Einheit einzeln zugeordnet werden.
Wenn ein Spracherkennungs-System diskret arbeitet, könnte es trotzdem kontinuierlich Gesprochenes verstehen. Dazu müsste aber jeder Satz als Referenzmuster gespeichert sein. Dadurch könnte der Satz "Die Sonne lacht" zwar erkann werden, eine geringfügige Änderung an dem Satz (bspw. "Die Anne lacht") hingegen nicht.
Bei Texterfassungssystemen wird differenziert, ob sich die Sprecher-Unabhängigkeit nur auf das System oder auch auf den Wortschatz bezieht. Ist das System sprecherunabhängig, der Wortschatz aber nicht, dann muss für jeden Benutzer ein eigener Wortschatz angelegt werden. Ein äußerst aufwendiger Prozess. Ist hingegen auch der Wortschatz unabhängig, dann werden nur die Referenzmuster an den Sprecher angepasst. Da es bedeutend weniger Referenzmuster gibt als Worte, spart ein sprecher-unabhängiger Wortschatz sehr viel Zeit.
Bei der Anpassung des Systems an den Sprecher wird geprüft, wie der Sprecher bestimmte Wort ausspricht ("wichtig"/ "wichtich"/ "wischtisch"). Eine Dialekterkennung ohne Initialtraining ist sogar für Menschen schwierig. Ein Anpassungstraining daher sehr empfehlenswert.